MIMbuild: The Multiple Indicator Model Builder
10.1 Introduction
MIMbuild helps find a set of recursive linear structural equation models with latent variables that share a common pure measurement model and explain patterns of vanishing tetrad differences judged to hold in the population. The user must provide a unidimensional measurement model and data for continuous variables, either as a covariance matrix or as raw data. MIMbuild searches among the different structural models, each of which is interpreted as a hypothesis about the causal structure among the latent variables. The Purify module (see chapter 9) can be used to find unidimensional measurement models.[1]
Structural equation models in which each latent variable is measured by several indicators are often called multiple indicator models (Fig. 10.1).

Fig. 10.1: A Multiple Indicator Model
Let T be the set of latent variables and V the set of measured indicators. Such models can be divided into two parts, the structural model (Fig. 10.2) and the measurement model (Fig. 10.3).
![]()
Fig. 10.2: The Structural Model
The graph of the structural model contains the members of T and edges between members of T, and the graph of the measurement model contains all of the variables (T È V) and the edges not in the graph of the structural model.

Fig. 10.3: The Measurement Model
We say a measurement model is pure, or unidimensional, if each indicator xi is the cause of no variable, is a direct effect of exactly one latent variable and an error term ei, and for every other error variable ej, ei and ej are uncorrelated. In what follows we use the terms unidimensional and pure interchangeably.
If the data are multivariate normal and the measurement model pure, MIMbuild can test for vanishing correlations and vanishing first order partial correlations among the latent variables. It uses these statistical facts to determine features of the causal structure among the latent variables.
MIMbuild takes as input:
• A covariance matrix or raw continuous data.
• A unidimensional measurement model.
It gives as output:
• Its statistical conclusions regarding the set of correlations and first order partial correlations that vanish among the latent variables.
• A pattern that represents a set of structural models that entail the same set of vanishing correlations and vanishing first order correlations.
Session 10.1 shows a MIMbuild run on data generated from an arbitrary parameterization of the model in Fig. 10.1. The input file mim.in contains a /Covariance section, and a /Graph section that specifies the measurement model shown in Fig. 10.3. One can also specify the covariance data and the measurement model in separate input files. If separate files are used, the file containing the /covariance section should be input before the file containing the /Graph section.
Session 10.1
************************************************
>input
Input
File: mim.in
>mimbuild
Output
file: mim.out
MIMBUILD:
A
Program to Build Linear Latent Variable Models
Reading
initial measurement model.
Mark
uncertain adjacencies? (y/n) [n] <CR>
>exit
************************************************
MIMbuild's output for this case is in the file mim.out and is as follows (Fig. 10.4).
################## mim.out
#################
MIMBUILD:
A
Program to Build Linear Latent Variable Models
--------------------------------------------------
Statistical
conclusions about the structural model
Edge (Partial)
Removed Correlation
------- -----------
T1
-- T4 rho(T1 T4) = 0
T2
-- T4 rho(T2 T4) = 0
T1
-- T3 rho(T1 T3 . T2) = 0
--------------------------------------------------
Pattern for the Structural Model
T1
-- T2
T2
-> T3
T3
<- T4
################## mim.out
#################
Fig. 10.4: MIMbuild output
For these data, MIMbuild's statistical conclusions are correct. No matter how the causal structure shown in Fig. 10.1 is parameterized, rT1,T4 = rT2,T4 = rT1,T3.T2 = 0 in the population. From these statistical facts MIMbuild concludes that T2 is a cause of T3, T4 is acause of T3, and T1 and T2 are causally adjacent, although here the direction of causation cannot be distinguished.
![]()
Fig. 10.5: Pattern of MIMbuild's Causal Conclusions
Another example illustrates MIMbuild's limitations. In this case, the model used to generate the data is an arbitrary parameterization of the model shown in Fig. 10.6.
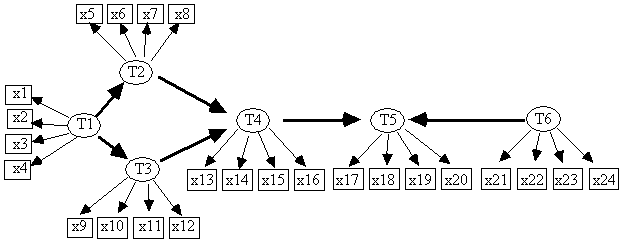
Fig. 10.6: Generating Model
The data are in the file mim2.dat, .dat;and the initially specified measurement model is given as a /Graph section in the file mim2.imm, which is shown pictorially in Fig. 10.7.
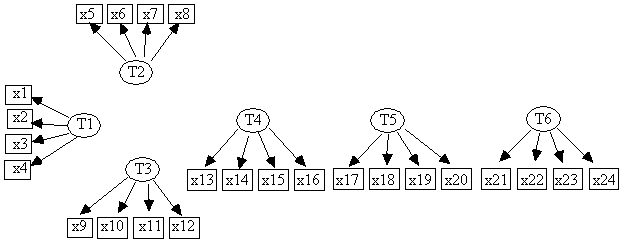
Fig. 10.7: Initially Specified Measurement Model
In this case (session 10.2) we respond yes to MIMbuild's query about marking uncertain adjacencies.
Session 10.2
************************************************
>input
Input File: mim2.dat
>input
Input File: [mim2.dat]mim2.imm
>mimbuild
Output file: mim2.out
MIMBUILD:
A Program to Build Linear Latent Variable Models
Reading initial measurement model.
Mark uncertain adjacencies? (y/n) [n] y
>exit
************************************************
In this case the output is more complicated.
################# mim2.out ###############
--------------------------------------------------
Statistical conclusions
about the structural model
Edge (Partial)
Removed Correlation
------- -----------
T1 -- T6 rho(T1 T6) = 0
T2 -- T6 rho(T2 T6) = 0
T3 -- T6 rho(T3 T6) = 0
T4 -- T6 rho(T4 T6) = 0
T1 -- T5 rho(T1 T5 . T4) = 0
T2 -- T3 rho(T2 T3 . T1) = 0
T2 -- T5 rho(T2 T5 . T4) = 0
T3 -- T5 rho(T3 T5 . T4) = 0
--------------------------------------------------
Pattern (set of indistinguishable causal models)
for the Structural Model
T1 ?--? T2
T1 ?--? T3
T1 ?--? T4
T2 ?->? T4
T3 ?->? T4
T4 -> T5
T5 <- T6
##################### mim2.out
##################
Fig. 10.8: Output File mim2.out
There are two differences between this and the previous example. First, even though MIMbuild's statistical decisions about the set of vanishing correlations and first-order partial correlations among the latent variables are correct, MIMbuild's output includes an undirected edge that does not exist in the generating model, namely T1-T4. Second, some of the edges contain a "?," which indicates that MIMbuild does not have enough information, even if its assumptions and statistical decisions are correct, to say for sure that T1-T4 are adjacent in the true model. The T1-T4 adjacency is included in the output pattern because in this case the algorithm cannot reliably remove the adjacency unless a second-order partial correlation among the latents, rT1,T4.T1,T3, is known to vanish, and the current version of MIMbuild cannot test it. The current version of MIMbuild cannot test for higher than first-order partial correlations among the latent variables. On the other hand, we have included "?"s on adjacencies that might be removable if MIMbuild could test for vanishing partial correlations of higher than first-order. Thus, the T1-T4 adjacency is surrounded with "?"s to indicate that it might not exist in the generating model. Other edges in the pattern that are surrounded with "?"s do exist in the generating model. Thus the existence of a "?" does not mean that the edge is not in the generating model, it simply means that MIMbuild cannot be certain either way, even if its assumptions are satisfied and it makes all statistical decisions correctly.
10.2 MIMbuild's Assumptions
MIMbuild operates on structural equation models in which it is assumed that each variable is a linear combination of its immediate causes plus a unique error variable, and the joint distribution is multivariate normal. In addition, MIMbuild requires that the measurement model input be unidimensional, and that it have at least three indicators for each latent. MIMbuild assumes that the structural model is recursive. The reliability of its output also depends upon the correctness of the initial measurement model.[2]
Unlike Purify, MIMbuild also assumes that the set T of latent variables specified in the measurement model is causally sufficient. That is, T includes all common causes of pairs of variables in T (see the discussion in chap. 2, section 2.3).
10.3 Syntactic Requirements of the Input
The syntactic limitations on MIMbuild's inputs are the same as those of Purify. Consult chapter 9, section 9.5.
10.4 Simulation Studies
Study 1: MIMbuild with a Pure Measurement Model
MIMbuild's asymptotic theoretical reliability is documented in Appendix D, but its reliability on samples of realistic size is best explored with simulated data. Besides its basic assumptions concerning linearity, several factors affect MIMbuild's performance: the sample size, the significance level of its hypothesis tests, the number of indicators per latent, the proportion of indicators that are actually pure[3], and so on.
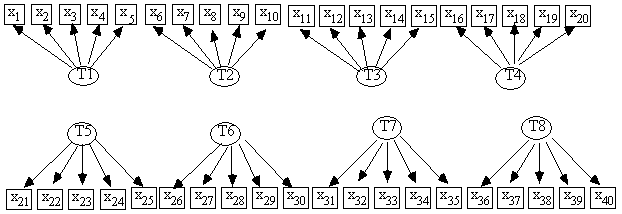
Fig. 10.9: Generating Measurement Model
MIMbuild makes a series of statistical tests of vanishing tetrad differences. It uses the results of these tests to calculate the Tetrad-score of models it considers, which in turn is used to select a model. The Tetrad-score is a measure of how closely the set of tetrad differences entailed to vanish by a model match the set of tetrad differences judged to vanish in the population.[4] The Tetrad-score is affected by two parameters, the significance level and the weight. We have found that the weight parameter does not affect the performance of MIMbuild, so we suggest leaving it at its default value.
In the first simulation study our purpose is to examine MIMbuild's reliability as a function of sample size and the significance level of the statistical tests that it uses,[5] so all of MIMbuild's basic assumptions are satisfied. That is, the data were generated from a recursive latent variable model with a unidimensional measurement model, the correct measurement model was given as input, the population was multinormal, and so on.
We began with the measurement model in Fig. 10.9. We then randomly generated a structural model by adding an edge from Ti to Tj (i < j) if a uniformly distributed [0,1] pseudo-random number was above .66. Because there are 28 possible edges, the expected number of edges was thus 9.33. Having a full generating model, we then gave each error variable a standard normal distribution, and pseudo-randomly selected the linear parameters from a uniform distribution with a lower limit of .5 and an upper limit of 1.5. We then drew a pseudo-random sample. We repeated this process 10 times each for n = 100, 250, 500, 1,000, and 2,500. So every sample analyzed came from a different randomly generated, randomly parameterized model. We applied MIMbuild to each sample three times, once with the significance level a = .05, once with a = .1, and once with a = .2, automatically recording its performance on a number of dimensions. Each point in the following graphs is an average for the 10 samples drawn at that setting.
We recorded the ratio of the number of adjacencies in the structural model MIMbuild erroneously omitted (committed) over the number it could have omitted (committed). From simultaneous tests performed on measured variables, the program is able to limit errors of adjacency omission to fewer than 10%, and able to limit its errors of adjacency commission (that it could have removed with 0 or first-order tests) to under 3%.

Fig. 10.10: Overall Adjacency Omission

Fig. 10.11: Overall Adjacency Commission
Purify and MIMbuild in
Sequence
Because Purify is meant to output a unidimensional measurement model, which is the input to MIMbuild, we ran a series of similar simulations in which we applied the two procedures in sequence. In the first study we randomly generated latent variable models in the way we describe in chapter 9, section 9.8. Approximately 50% of the indicators in such models were impure. We gave each sample to Purify, and then gave the measurement model output by Purify and the corresponding subsample to MIMbuild. As the following plots show, MIMbuild's reliability was not compromised by using the output of Purify as input to MIMbuild.


MIMbuild with Impure Measurement Models
Even if MIMbuild's statistical decisions are all correct, its tests of vanishing correlation and first order vanishing partial correlations used to determine the adjacencies in the structural model are reliable only if the measurement model it uses is pure or almost pure. To gauge the effect of impurities on MIMbuild's ability to detect structural model adjacencies, we performed the following simulation study.
Beginning with the skeleton in Fig. 10.12 below, we again randomly generated a structural model, including just over a third of the possible structural edges.
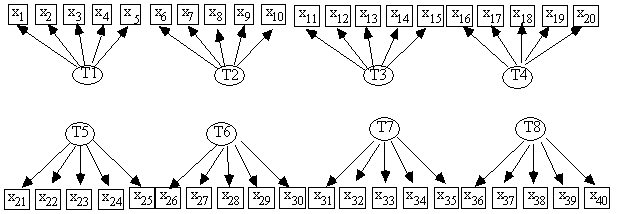
Fig. 10.12: Skeleton
In this study we systematically varied the proportion of indicators that were made impure from 0 to 70%. At 70% , 28 of the 40 measures are impure in the model that generated the data. After randomly parameterizing each generating model, we generated 10 samples of n = 500, and analyzed each sample in two ways. In both we set the weight at 1.0 and the significance level at .05. In the first version we ran Purify and then MIMbuild on Purify's output measurement model, and in the second only MIMbuild on the measurement model in Fig. 10.12. The next two plots compare the reliability of adjacency detection in the two procedures. As Fig. 10.13 shows, it is actually somewhat better to leave impure indicators in the model if one's only goal is to avoid omitting adjacencies. In contrast, failure to purify a measurement model leads to disasterous overfitting in which, with about 50% of the indicators impure, almost every adjacency is postulated. Fig. 10.14, in which the linear trends are plotted, shows the benefit of purifying.

Fig. 10.13

Fig. 10.14